本文将为大家介绍C语言标准(ISO/IEC 9899)中的所有翻译阶段,以及字符串字面量(string literal)的语法特性,最后再结合 _Pragma 单目操作符表达式的使用做综合说明。
C语言中的翻译阶段
C语言标准中在5.1.1.2小节明确指出了8个翻译阶段,并且也备注了C语言编译器实现在行为上应该表现出这八个独立的阶段确实发生了,即便它们在实际实现优化上可以进行折叠。
下面我们就来看看C语言标准中的描述。为了不引入歧义,这里将原文与笔者的译文分别给出进行,方便各位可以对照地看。
【原文】The precedence among the syntax rules of translation is specified by the following phases.
【译文】以下阶段指定了翻译语法规则之间的先后次序。
1、【原文】Physical source file multibyte characters are mapped, in an implementation defined manner, to the source character set (introducing new-line characters for end-of-line indicators) if necessary. Trigraph sequences are replaced by corresponding single-character internal representations.
【译文】物理上的源文件多字节字符若有必要,以一种实现定义的方式映射到源字符集(对于行结束指示符引入换行字符)。三字符序列用其相应的单字符内部表示进行替换。【译者注:这里开头的单词Physical其实对应于“逻辑上的”,即Logical。三字符序列是因为某些国家语言文字不支持某些ASCII字符而引入的三字符序列替代品。比如,??( 对应于 [ 符号。不过C11标准之后,三字符序列表示就被声明为废弃了,取而代之的是可以用更现代化的在C语言标准中6.4.6节所描述的复合字符(digraph)作为替代品。比如,复合字符 <: 表示 [ 。】
2、【原文】Each instance of a backslash character (\\) immediately followed by a new-line character is deleted, splicing physical source lines to form logical source lines. Only the last backslash on any physical source line shall be eligible for being part of such a splice. A source file that is not empty shall end in a new-line character, which shall not be immediately preceded by a backslash character before any such splicing takes place.
【译文】紧靠在换行字符之前的每个倒斜杠字符(\\)的实例都被删除,将物理源代码行进行拼接以形成逻辑源代码行。只有在物理源代码行处的最后一个倒斜杠才有资格作为这么一次拼接的一部分。一个内容不空的C语言源文件应该以一个换行符结束,而这个作为源文件结束的换行符之前不应该紧跟着任一倒斜杠字符。
3、【原文】The source file is decomposed into preprocessing tokens and sequences of white-space characters (including comments). A source file shall not end in a partial preprocessing token or in a partial comment. Each comment is replaced by one space character. New-line characters are retained. Whether each nonempty sequence of white-space characters other than new-line is retained or replaced by one space character is implementation-defined.
【译文】源文件被分解为预处理符号与空白字符序列(包括注释)。一个源文件不应该以一种部分预处理符号或是部分注释的状态下结束。每条注释用一个空格字符替代。换行字符被保留。除了换行符以外的每个非空空白字符序列是保留还是用一个空格字符替代,这是由实现定义的。
4、【原文】Preprocessing directives are executed, macro invocations are expanded, and _Pragma unary operator expressions are executed. If a character sequence that matches the syntax of a universal character name is produced by token concatenation (6.10.3.3), the behavior is undefined. A #include preprocessing directive causes the named header or source file to be processed from phase 1 through phase 4, recursively. All preprocessing directives are then deleted.
【译文】预处理指示符被执行,宏调用被扩展,并且 _Pragma 单目操作符表达式被执行。如果匹配通用字符名语法的字符串通过符号拼接(6.10.3.3,即 ## 预处理器符号)产生,那么行为是未定义的。【译者注:通用字符名在C11语言标准中的6.4.3小节中描述,即通过 \\u 或 \\U 后面跟十六进制数所表示的字符名,比如:\\u0024 表示 $ 字符。而这里C语言标准明确提到了,在上述预处理器执行时,不能通过 ## 拼接符来形成一个通用字符名。】一个 #include 预处理指示符引发名命的头文件或源文件从阶段1到阶段4进行递归地处理。所有预处理指示符随后被删除。
5、【原文】Each source character set member and escape sequence in character constants and string literals is converted to the corresponding member of the execution character set; if there is no corresponding member, it is converted to an implementation-defined member other than the null (wide) character.
【译文】每个源字符集成员与字符内容和字符串字面量中的转义序列被转换为对应的执行字符集成员;如果没有对应的成员,那么它将被转换为由实现定义的成员,而不是空(宽)字符。
6、【原文】Adjacent string literal tokens are concatenated.
【译文】邻近的字符串字面量符号被拼接。
7、【原文】White-space characters separating tokens are no longer significant. Each preprocessing token is converted into a token. The resulting tokens are syntactically and semantically analyzed and translated as a translation unit.
【译文】分隔符号的空白字符不再重要。每个预处理符号被转换为一个符号。生成的结果符号在语法上和语义上作为一个翻译单元进行分析和翻译。
8、【原文】All external object and function references are resolved. Library components are linked to satisfy external references to functions and objects not defined in the current translation. All such translator output is collected into a program image which contains information needed for execution in its execution environment.
【译文】所有外部对象与函数引用被解决。库组件被连接以满足对没有定义在当前翻译中的函数与对象的外部引用。所有这种翻译器输出被收集形成一个程序图,它包含了在其执行环境中所需要的信息。
以上就是C语言编译器要做的所有该做的翻译阶段。我们可以看到,上述8个阶段中,阶段1到阶段7均会对预处理符号进行处理。而在阶段7中才将所有预处理符号(preprocessing token)转换后移除。下面为大家做一个以上8个阶段的概述总结:
- 阶段1:将物理源文件中的字符集映射为源字符集,并且将三字符序列转换为单字符内部表示。
- 阶段2:移除冗余的行尾的倒斜杠。
- 阶段3:将源文件分解为预处理字符与空白符序列,并将注释转换为空格符(由实现定义)。
- 阶段4:执行预处理指示符、扩展宏调用,以及执行 _Pragma 单目操作符表达式。最后删除所有预处理指示符。
- 阶段5:翻译字符常量与字符串字面量中的转义字符序列。
- 将相邻的字符串字面量符号进行拼接。(我们下面会详细描述)
- 将每个预处理符号转换为一个符号,并开始做语法和语义上的分析与翻译。
- 解决外部对象和函数引用。
这里大家需要注意的是,字符串字面量的拼接发生在阶段6,要晚于阶段4时所处理的 _Pragma 单目操作符表达式,因此这也就意味着我们不能通用字符串拼接的形式形成对 _Pragma 操作符的参数来使用。后面会详细讨论到。
C语言中的字符串字面量拼接
C语言的字符串字面量有一个很神奇的特性:为了方便连接多个字符串,C语言标准提供了字符串字面量的拼接语法,可使得多个字符串字面量之间可通过插入0个或多个空白符(包括换行符)进行自然相连拼接,最后形成一串完整的字符串。我们看以下代码截图。
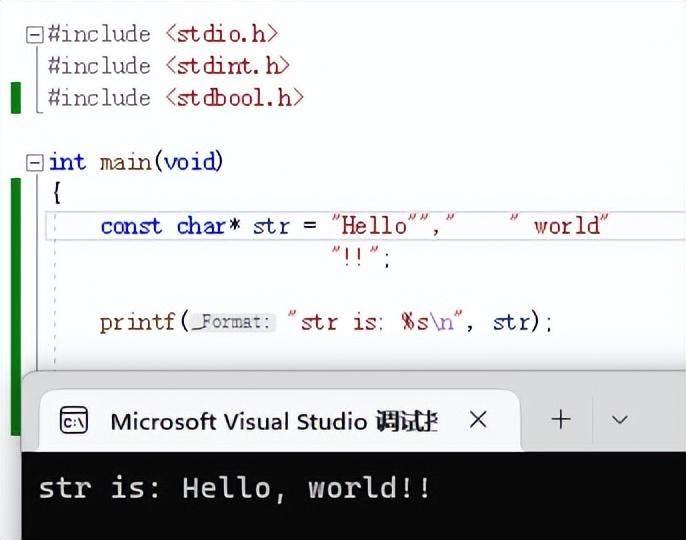
上图代码中有四个字符串字面量进行拼接:“Hello”、“,”、” world” 以及 “!!”,最后形成完整的字符串——“Hello, world!!”。其中,“Hello” 与 “,” 之间没有任何空白符;而 “,” 与 ” world” 之间有4个空格字符;而 ” world” 与 “!!” 之间则由一个换行符外加多个空格分隔。
另外,C11标准中引入了UTF-8、UTF-16以及UTF-32字符编码表达形式。同样对于这些字符编码形式的字符串字面量也依旧能进行拼接,看以下代码截图。
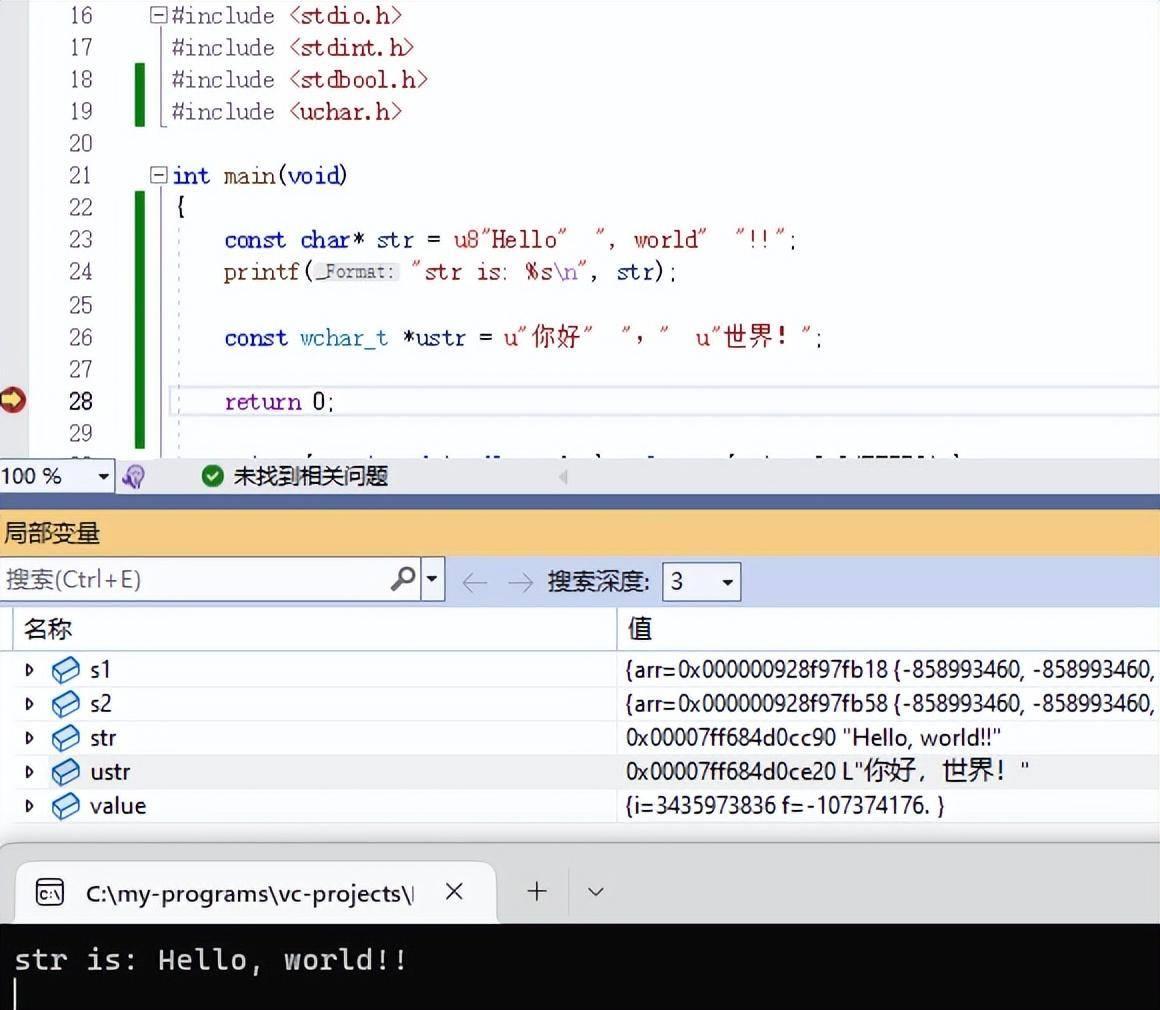
我们可以看到,在后续字符串字面量中,表示当前字符串编码形式的前缀(u8、u或U)是可缺省的。此外,由于在当前Visual Studio环境下使用C11标准关键字 char16_t 无法在调试器中正常观察到正确的UTF-16字符串内容,因此这里选用了 wchar_t 类型,尽管这不属于规范写法。
以上就是我们所讲的C语言中的字符串字面量的拼接语法特性。
_Pragma操作符中不能使用字符串字面量的拼接
C99标准中引入了 _Pragma 单目操作符来取代某些情况下对 #pragma 预处理指示符的使用。由于为了跨平台,我们可能需要对某些硬件系统环境启用与其他环境不同的编译开关,因此很自然地会想到通过宏进行平台相关代码的隔离。但是C90标准中所引入的 #pragma 其本身就是预处理指示符了,因此无法与 #define 宏定义预处理器指示符结合使用。因此C99标准引入了 _Pragma 单目操作符表达式以便在宏定义中能做某些编译开关。
前面我们提到了,_Pragma 单目操作符表达式的执行发生在翻译阶段4,要早于发生在翻译阶段6的字符串字面量拼接。因此对于整个 _Pragma 单目操作符表达式而言,它是无法处理字符串拼接的。我们看以下代码截图。
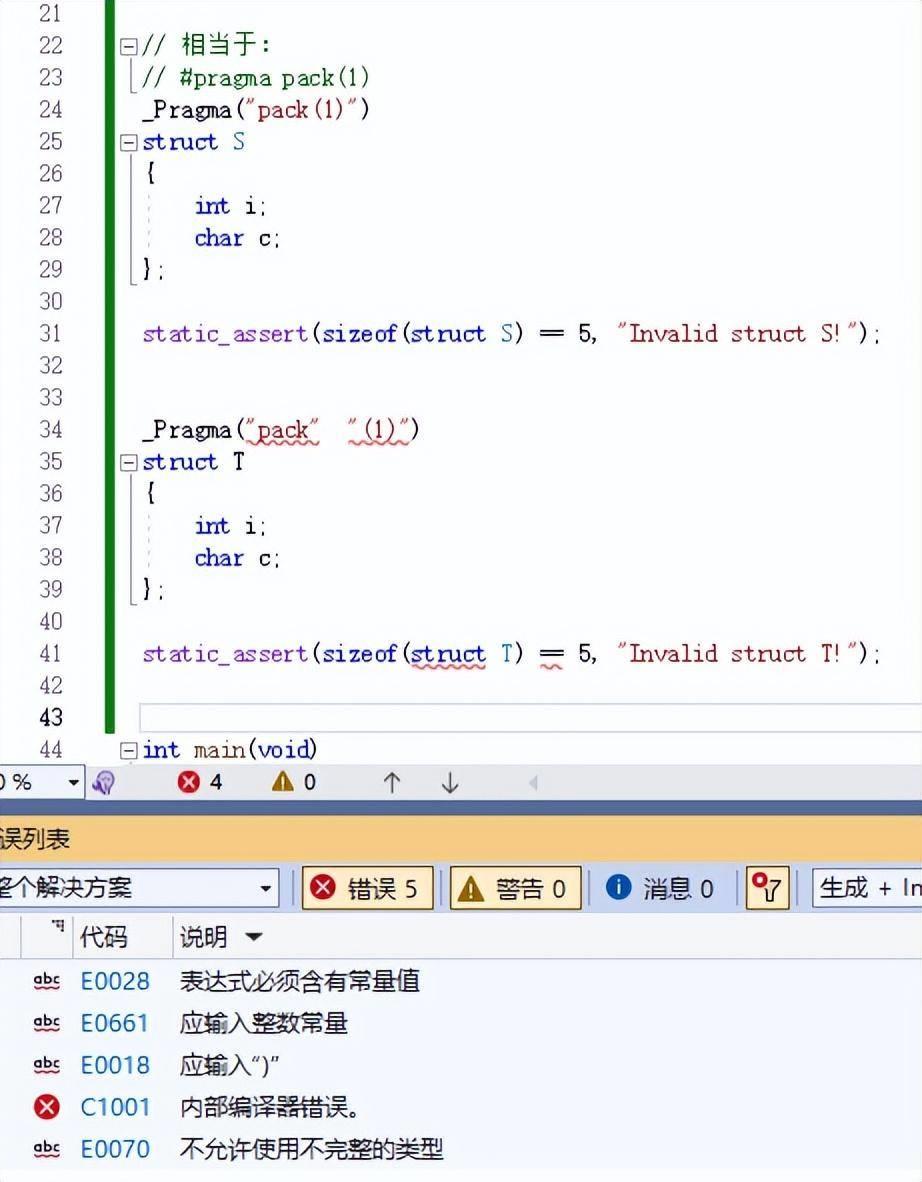
上图很明显能看到,对第二个结构体 T 的 _Pragma 表达式的编译会引发报错。
那我们平时一般会用何种技巧来简化对_Pragma 单目操作符表达式的使用呢?其实也不复杂。我们可以将pragma的开关里的内容作为一个整体,然后通过 # 预处理操作符做整体的字符串化即能解决问题。而pragma里面的内容是可自由拼接的。我们可以看以下代码:

上述截图可以看到,Visual Studio 2022 Community Edition在智能感知上可以对宏做一次扩展,不过基本也能容易获得第二次展开之后的结果,并且也是用注释标明了。