近期有些网友想要了解搜索引擎原理介绍的相关情况,小编通过整理给您分析,同时介绍一下终于明白它的原理了有关信息。

在互联网时代,搜索引擎可以说是日常生活的一部分。不仅如此,搜索引擎历经20多年的风霜雨雪,仍然牢牢占据着流量入口,不得不让人感叹。
而且,提起搜索引擎,我们都会想到一家高大上的巨无霸公司和一家被黑出xiang的巨霸公司。足以见得搜索引擎的巨大作用。


作为产品人,对此当然不能视而不见,也应该了解了解其工作原理。
搜索引擎工作原理大致可以分为3个步骤
1. 爬行与抓取
2. 预处理
3. 排序
所谓一图胜千言,没图我说个……
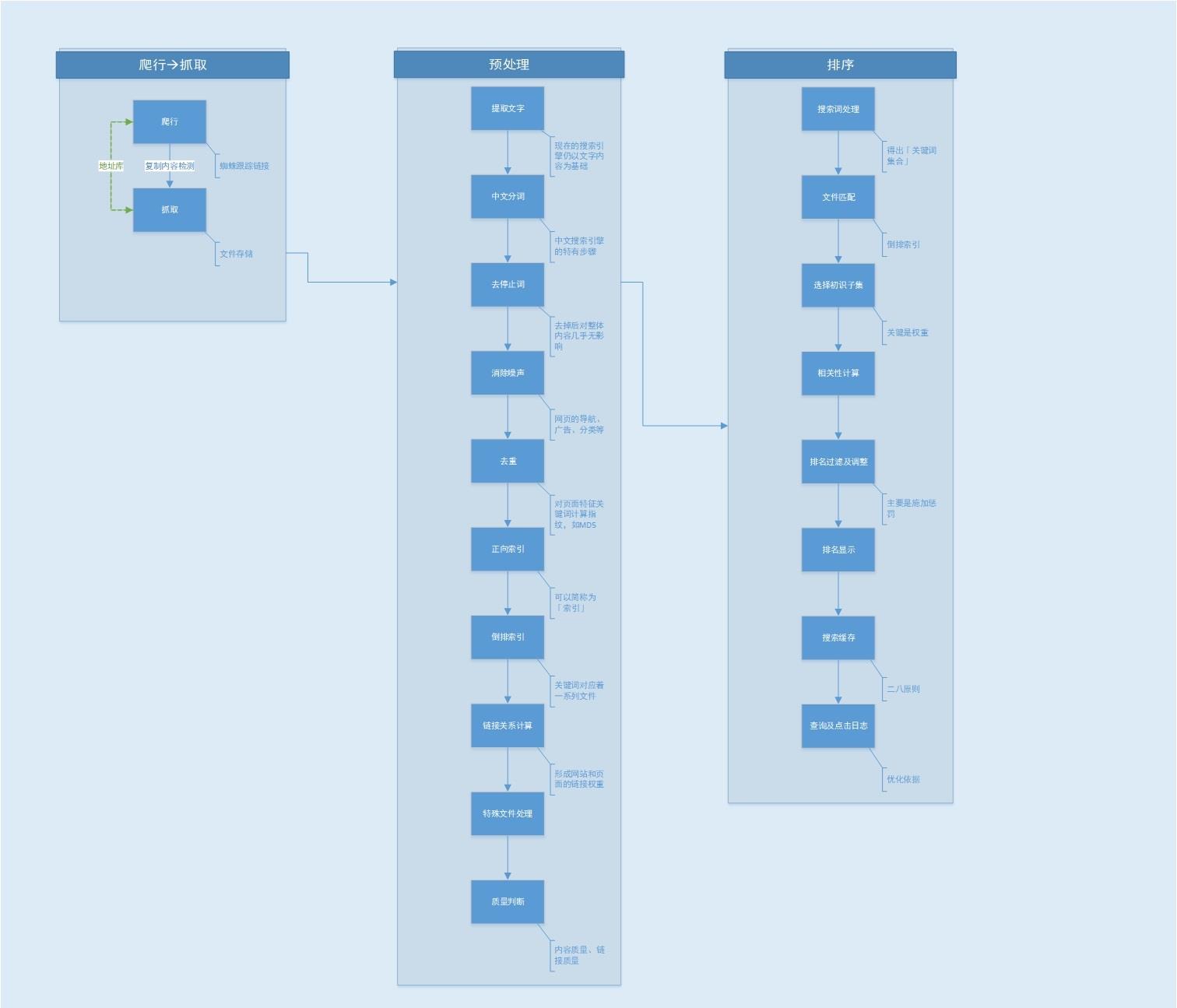
PS:上图总结自《SEO实战密码》。
下面详细叙述:
爬行与抓取
简单地说:就是搜索引擎蜘蛛沿着互联网络爬行并抓取其爬行的页面,将这些抓取的页面存储起来。
说到这,你可能会问:为什么叫「蜘蛛」?
为了抓取尽量多的页面,搜索引擎会跟踪页面上的链接,从一个页面爬行到下一个页面,好像蜘蛛在蜘蛛网上爬行那样,这就是搜索引擎蜘蛛这个名称的由来。
搜索引擎在跟踪网络上的链接时,会使用一定策略,因为现在的网络链接太多。最简单的爬行遍历策略有两种,一种是深度优先,一种是广度优先。
还有一点值得一提:搜索引擎访问网站页面时类似于普通用户使用的浏览器。搜索引擎蜘蛛抓取的数据存入原始页面数据库,其中的页面数据与用户浏览器得到的HTML完全一样。
预处理
由于抓取的页面数量太大(以”亿”为单位),无法快速实时排序,所以需要预处理。这就是产品设计中的「复杂性守恒原则」,我们没办法让用户等待十几秒甚至更久,就只能在后台处理上下功夫。
在一些资料中,「预处理」也被称为「索引」,因为「索引」是预处理最主要的内容。
预处理的过程比较复杂,值得一提的有这么几点:
- 去重:对于内容相似度高的,搜索引擎不喜欢,因为用户不喜欢这样的内容。而且,搜索引擎的去重算法很可能不止于页面级别,而是进行到段落级别。因此,混合不同文章、交叉调换段落顺序也不能使转载和抄袭变成原创。所以,少抄袭,多原创吧。
- 正向索引:可以简称为「索引」。通过这个步骤,搜索引擎将页面及关键词形成词表结构存储进索引库。简化的索引词表形式如下。你看,这样就得到了每个文件(如每个页面)的对应关键词。这样用户就能搜索了吗?还不行。

- 倒排索引:正向索引虽然提供了文件与关键词的对应关系,但无奈用户搜索的是关键词,因此搜索引擎还需根据这些对应关系找到某关键词对应的文件,这样的计算量无法满足实时返回排名结果的要求。因此,还需要倒排索引。倒排索引与正向索引刚好相反,它以关键词为关键,简单来说如下表:

得到了倒排索引,就能很快地根据用户搜索的关键词找到对应文件,但这样就够了吗?别天真啊。
通过上述步骤,其实只得到了页面本身的内容。说白了,就是页面本身告诉搜索引擎自己如何如何。
俗话说:王婆卖瓜,自卖自夸。
就像我们网购时不仅会看店家给的商品介绍,还会看看买家的评论一样,页面内容质量,也需要其他人的评价——这里的「其他人」指「其他页面。」所以,我们还需要链接关系计算。
- 链接关系计算:每个页面上都有链接,不同页面之间用链接互相关联起来,这些关联关系,就形成了其他页面对某个页面的评价。这些复杂的链接指向关系形成了网站和页面的链接权重。
排名
发现没有:排名,是用户是用户唯一能感觉到的步骤,爬行与抓取、预处理,都在后台完成。正因如此,用户才会感到用起来十分快捷。
排名的过程也比较复杂,其中值得一提的有如下几点:
- 搜索词处理:说白了,就是处理用户输入的关键词。这一步对用户来说更为关键,因为搜索引擎还不够智能,需要我们去学习一些高级指令,以获得更为精准的内容。
但由于每个关键词对应的文件数量都可能是巨大的(如几亿个),处理如此庞大的数据量,无法满足用户对「快」的需求。同时,用户并不需要所有内容,他们往往只查看前几页内容,甚至很多用户只查看第一页的前几条内容。因此,选择一定数量的内容进行处理,很有必要。这就涉及到选择初识子集。
但如何选择呢?这是一个问题。
- 选择初识子集:选择出示子集,关键在于「权重」。所以说权重有多重要,即使页面做得好,但权重不高,连做备胎的机会都没有。
- 相关性计算:这是排名过程中最重要的一步,最终搜索结果页面的排名基本按照相关性从高到低排序。
但到此就结束了吗?还没有哦。
- 排名过滤及调整:为了保证用户搜索结果更符合用户需求,搜索引擎需要过滤掉那些处心积虑钻空子的页面,在这一步,搜索引擎会找出这些页面并施加惩罚。典型的例子是百度的11位。所以,过度优化有风险。
- 查询及点击日志:通过这一步,搜索引擎记录了用户的一些数据,从而为后续的优化提供依据。这和产品日常工作中的数据埋点有些相似。